近日,學院四川省油氣勘探開發智能化工程研究中心在知識檢索和自然語言處理領域的研究中取得新進展,分別在ACM International Conference on Information and Knowledge Management(CIKM 2024)和Conference on Empirical Methods in Natural Language Processing(EMNLP 2024)發表系列學術論文。
2022級碩士生付勛擔任第一作者,謝文波老師、王欣教授指導,碩士生陳斌、鄧濤、鄒甜共同參與的論文《ACDM: An Effective and Scalable Active Clustering with Pairwise Constraint》被CIKM 2024錄用。CIKM會議是信息檢索和數據挖掘領域的頂級國際會議,屬于CCF推薦的B類國際學術會議。2024年CIKM共收到1496篇有效投稿,最終錄用347篇,錄用率僅為23%。這是該團隊首次在該會議發表論文。代碼鏈接:https://github.com/briceloskie/ACDM。
論文提出了一種主動聚類擴散模型(ACDM)。ACDM利用最近鄰技術構建擴散圖,并通過在線框架迭代地改進聚類結果。在每次迭代中:(a) 以批處理方式選擇具有高不確定性和代表性的節點;(b) 使用基于鄰域集合的新型查詢,利用成對約束對所選節點進行分類;(c) 將已分類的節點作為擴散模型中的源節點,細化聚類。復雜性理論分析和實證評估均證明了該方法的有效性和可擴展性。值得注意的是,ACDM對數據相似度不敏感,適用范圍廣泛。該研究為主動聚類領域做出了重要貢獻,為大規模數據的管理提供了新的解決方案。
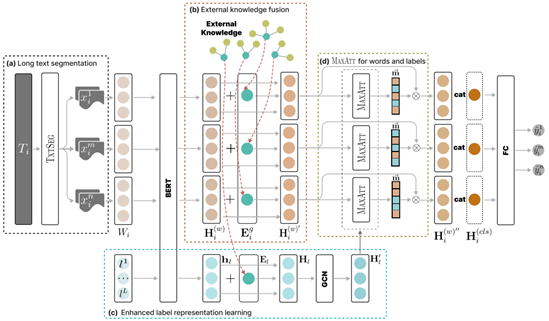
張望(2021級碩士生)、鄧濤(2023級碩士生)、吳曉茹(2023級碩士生)和王欣教授、王騫老師合作完成的論文 《From Text Segmentation to Enhanced Representation Learning: A Novel Approach to Multi-Label Classification for Long Texts》被自然語言處理國際會議EMNLP接收。該會議屬于CCF B推薦會議,在國際自然語言處理領域中享有較高聲譽。論文提出的LSKTC算法用于多標簽文本分類。在該任務中,每個樣本可以被分配多個類別標簽。現有大多數模型依賴于預訓練模型來提供高質量的文本表示。然而,當處理較長的文本時,由于預訓練模型對輸入長度的限制,這些模型會面臨挑戰。為了應對長文本分類的問題,論文引入了一個綜合性的解決方案,具體如下:1)文本分割算法:該算法旨在克服文本輸入長度限制的問題。算法能保證生成最優的文本分割結果,使得長文本可以被分割成更小的片段,然后再分別處理。2)外部知識和標簽共現:在表示學習過程中整合外部知識和標簽的共現信息,以增強文本和標簽的表示能力。這有助于捕捉文本和標簽之間復雜的關聯性,從而提升分類性能。3)有效性驗證:通過在多種MLTC數據集上進行廣泛的實驗,驗證了所提出方法的有效性。實驗結果也證實了論文的觀點:文本和標簽之間具有復雜的相關性。
論文的研究內容旨在改進長文本的多標簽分類性能,并通過利用文本內部結構和外部信息來增強模型的理解能力。這樣的研究不僅有助于解決實際應用中的長文本分類問題,也為進一步的研究提供了新的視角和技術手段。